Ok, kami telah membuat tabel terpisah
dan kunci utama di tabel pengguna, userId, sekarang terkait dengan kunci asing
di tabel url, relUserId. Kita dalam kondisi yang jauh lebih baik. Tapi apa
jadinya bila kita ingin menambah pegawai perusahaan ABC? Atau 200 karyawan?
Sekarang kami punya nama dan alamat perusahaan yang menduplikat dirinya sendiri
di semua tempat, sebuah situasi yang cukup mengenakkan untuk mengenalkan kesalahan
ke data kami. Jadi kita ingin melihat penerapan Third Normal Form:
Bentuk Normal Ketiga
1. Hilangkan
bidang yang tidak bergantung pada tombolnya.
Nama dan Alamat Perusahaan kami tidak ada hubungannya dengan User Id, jadi
mereka harus memiliki Id Perusahaan mereka sendiri:

Sekarang kita punya primary key compId di tabel
perusahaan yang berhubungan dengan foreign key di tabel pengguna yang disebut
relCompId, dan kita bisa menambahkan 200 pengguna sambil tetap hanya
menyisipkan nama "ABC" satu kali. Tabel
pengguna dan url kami dapat tumbuh sebesar yang mereka inginkan tanpa duplikasi
atau korupsi data yang tidak perlu. Sebagian
besar pengembang akan mengatakan Formulir Normal Ketiga cukup jauh, dan skema
data kami dapat dengan mudah menangani beban keseluruhan perusahaan, dan dalam
kebanyakan kasus mereka akan benar.
Tapi
lihatlah bidang url kami - apakah anda memperhatikan duplikasi data? Ini
bisa diterima jika kita tidak menentukan bidang ini. Jika
halaman masukan HTML yang pengguna kami isikan untuk memasukkan data ini
memungkinkan masukan teks formulir bebas tidak ada yang bisa kami lakukan
mengenai hal ini, dan ini hanya kebetulan bahwa Joe dan Jill sama-sama
memasukkan bookmark yang sama. Tapi
bagaimana jika itu adalah menu drop-down yang kita tahu hanya mengizinkan dua
url tersebut, atau mungkin 20 atau bahkan lebih. Kita
dapat mengambil skema database kita ke tingkat berikutnya, Formulir Keempat,
yang banyak diabaikan oleh pengembang karena bergantung pada jenis hubungan
yang sangat spesifik, hubungan banyak-ke-banyak, yang belum kita temukan dalam
aplikasi kita.
Hubungan Data
Sebelum
kita mendefinisikan Bentuk Normal Keempat, mari kita lihat tiga hubungan data
dasar: satu-ke-satu, satu-ke-banyak, dan banyak-ke-banyak. Lihatlah
tabel pengguna dalam contoh First Normal Form di atas. Sejenak
mari kita bayangkan kita meletakkan bidang url di meja terpisah, dan setiap
kali kita memasukkan satu record ke dalam tabel pengguna, kita akan memasukkan
satu baris ke dalam tabel url. Kami
kemudian akan memiliki hubungan satu-ke-satu: setiap baris di tabel pengguna
akan memiliki persis satu baris yang sesuai di tabel url. Untuk
keperluan aplikasi kami, hal ini tidak akan berguna atau dinormalisasi.
Sekarang
lihat tabel dalam contoh Second Normal Form. Tabel
kami memungkinkan satu pengguna memiliki banyak url yang terkait dengan catatan
penggunanya. Ini
adalah hubungan satu-ke-banyak, tipe yang paling umum, dan sampai kita mencapai
dilema yang disajikan dalam Third Normal Form, satu-satunya jenis yang kita butuhkan.
Hubungan
banyak-ke-banyak, bagaimanapun, sedikit lebih kompleks. Perhatikan
dalam contoh Third Normal Form kami memiliki satu pengguna yang berhubungan
dengan banyak url. Seperti
disebutkan, kami ingin mengubah struktur itu agar banyak pengguna terkait
dengan banyak url, dan karenanya kami menginginkan hubungan yang
banyak-ke-banyak. Mari
kita lihat apa yang akan kita lakukan pada struktur meja kita sebelum kita
membahasnya:

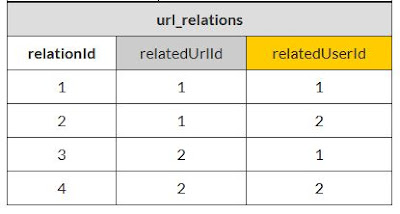
Untuk mengurangi duplikasi data (dan dalam proses membawa
diri kita ke Bentuk Normalisasi Keempat), kami telah menciptakan sebuah tabel
yang tidak memiliki apa-apa selain kunci utama dan kunci utama dalam
url_relations. Kami
bisa menghapus entri duplikat di tabel url dengan membuat tabel url_relations. Sekarang
kita dapat secara akurat mengungkapkan hubungan yang Joe dan Jill terkait
dengan masing-masing, dan keduanya, urlnya. Jadi,
mari kita lihat persis apa yang Dimulai dari Formasi Keempat Normalisasi:
Bentuk
Normal Keempat1. Dalam
hubungan banyak-ke-banyak, entitas independen tidak dapat disimpan dalam tabel
yang sama.
Karena
hanya berlaku untuk hubungan banyak-ke-banyak, kebanyakan pengembang berhak
mengabaikan peraturan ini. Tapi
itu sangat berguna dalam situasi tertentu, seperti ini. Kami
telah berhasil menyederhanakan tabel url kami untuk menghapus entri duplikat
dan memindahkan relasinya ke dalam tabel mereka sendiri.
Hanya
untuk memberi contoh praktis, sekarang kita bisa memilih semua url Joe dengan
melakukan panggilan SQL berikut ini:
Nama
SELECT, url FROM users, url, url_relations WHERE url_relations.relatedUserId =
1 DAN user.userId = 1 DAN urls.urlId = url_relations.relatedUrlId
Dan
jika kami ingin mengelompokkan informasi Pengguna dan Url setiap orang, kami
akan melakukan hal seperti ini:
Nama
SELECT, url FROM users, url, url_relations WHERE user.userId =
url_relations.relatedUserId DAN urls.urlId = url_relations.relatedUrlId
Bentuk Normal Kelima
Ada
satu lagi bentuk normalisasi yang kadang-kadang diterapkan, tapi memang sangat
esoteris dan dalam banyak kasus mungkin tidak diperlukan untuk mendapatkan
fungsi paling banyak dari struktur data atau aplikasi Anda. Prinsip
itu menyarankan:1. Tabel
asli harus direkonstruksi dari tabel yang telah dipecah.
Manfaat
menerapkan peraturan ini memastikan Anda belum membuat kolom asing di tabel
Anda, dan bahwa semua struktur tabel yang Anda buat hanya sebesar yang mereka
inginkan. Ini
adalah praktik yang baik untuk menerapkan peraturan ini, namun jika Anda tidak
berurusan dengan skema data yang sangat besar, Anda mungkin tidak
memerlukannya.
Saya
harap Anda telah menemukan artikel ini berguna, dan dapat mulai menerapkan
aturan normalisasi ini ke semua proyek database Anda. Dan
jika Anda bertanya-tanya dari mana semua ini berasal, tiga aturan normalisasi
pertama digariskan oleh Dr. E.F. Codd dalam makalahnya pada tahun 1972,
"Normalisasi Lebih Lanjut dari Model Relasi Data Base". Aturan
lainnya sejak itu telah berteori dengan kemudian Set Theory and Relational
Algebra matematikawan.
itu tadi sekian tutor dari saya semoga bermanfaat bagi semuanya. wassalam
FYI, ini adalah artikel yang saya tulis beberapa waktu yang lalu yang mendapat banyak perhatian selama ini. Sejak itu telah diterjemahkan ke dalam belasan bahasa dan diajarkan di beberapa universitas. Ini juga ada dalam daftar bacaan yang disarankan untuk kursus Ilmu Komputer Ekstensi Harvard. Ini
berlaku untuk bahasa pemrograman web manapun yang mengakses sistem
database, baik itu PHP dan MySQL atau ASP.NET dan Microsoft SQL Server.





















